HTTP 协议总结
概念:
HTTP(Hypertext Transfer Protocol): 是一种基于 TCP,用于互联网浏览器与服务器 web 应用通讯的超文本传输协议. 特点是 无状态(“浏览器对于事务的处理没有记忆能力” 只有客户端发起,服务器才返回请求,服务器不主动发起请求),无连接( 每次只处理一个请求),明文传输(http 本身不对传输数据加密)
1.资源
(Resources):
"Web servers host web resources".放在任何 web 服务器中 不限于图片,影像,文本等等的 可以通过互联网访问的文件 都可以叫做资源. 资源在网上不需要静态, 也可以是 像 JavaScript 程序一样的动态程序.
文档类型
(Media Types)
Http 支持的文档类型被叫做 MIME (Multipurpose Internet Mail Extensions),在浏览器从服务器访问资源之后,会查看文件是否支持和打开这个文档,并显示在屏幕上 或者下载到电脑里
下面有一些例子: An HTML-formatted text document would be labeled with type text/html. A plain ASCII text document would be labeled with type text/plain. A JPEG version of an image would be image/jpeg. A GIF-format image would be image/gif. An Apple QuickTime movie would be video/quicktime. A Microsoft PowerPoint presentation would be application/vnd.mspowerpoint.
2.URIs vs URLs
(Uniform resource identifier) vs (Uniform resource locator)
URIs 是服务器资源在互联网的唯一标识. 浏览器通过 URI 访问资源
URLs 是更大众化的资源地址,并告知浏览器怎样去得到这个资源.URLs Syntax
:// : @ : / / ? #
主要的三部分为: scheme: 告诉浏览器怎样去访问资源(e.g.,http://) Internet address: 服务器地址 (e.g., Link). The rest names a resource: 资源在服务器上的路径与名称 (e.g., /specials/saw-blade.gif ).
简单来说 URLs 是 URI 的一部分,URL 一定是 URI 但是 URI 不一定是 URL. URI 的另一部分 叫做 URNs(uniform resource name)
3.通讯
(Transactions):
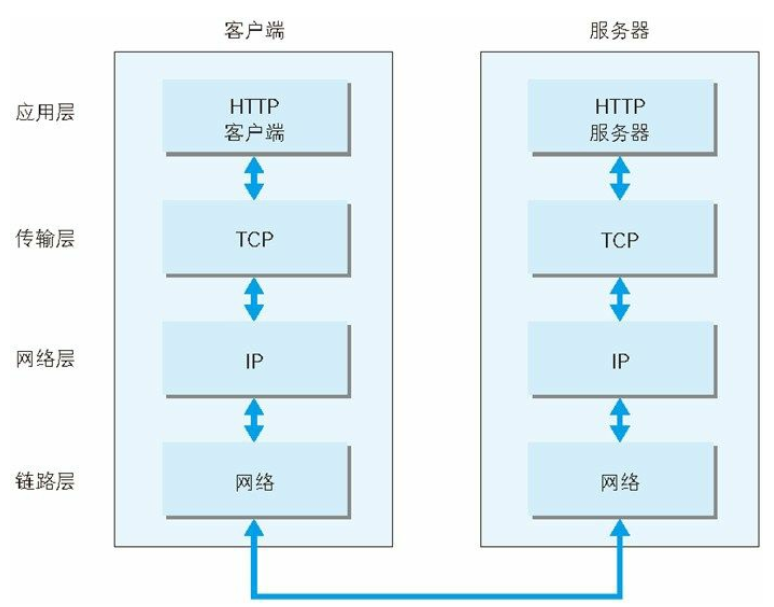
http 通讯建立在 tcp 基础上, 流程为 tcp 三次握手建立链接(syn,ack) =>客户端发送数据=>服务器返回数据=>4 次挥手后关闭对话. 具体关系(Figure 1-9. HTTP network protocol stack)
理论上 在 Http 协议中 每次通讯请求(request)都会应该得到一个回复(response), 请求应包括 start line 和 Header fields 头文件(必选) 和 body(可选),回复(response) 中包括 状态码(Status Codes) 以及 其他内容的资源
ref:Link
方法:(Methods):
Http 常用方法包括 post (发送), get (接收) ,delete(删除), put (修改),head (只发送 header). RestAPI 协议基于这些方法开发出来的协议. get/head/delete 方法请求只发送头文件, post/put 方法会发送 body. get/head 是对服务器安全 因为通常情况下不会修改服务器数据.
OPTIONS: 对服务器发起请求,以检测服务器支持哪些 HTTP 方法
包含:
HTTP/1.1 200 OK Allow: OPTIONS, GET, HEAD, POST Cache-Control: max-age=604800 Date: Thu, 13 Oct 2016 11:45:00 GMT Expires: Thu, 20 Oct 2016 11:45:00 GMT Server: EOS (lax004/2813) x-ec-custom-error: 1 Content-Length: 0
客户端请求消息(request):
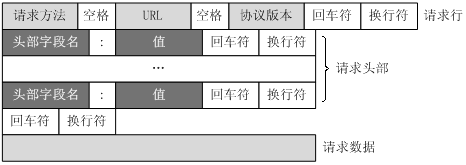 (ref:Link)
(ref:Link)
服务器响应消息(response):
HTTP 响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文
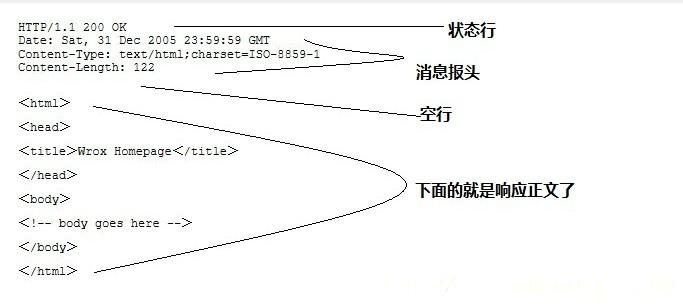
(ref:Link)
状态码(Response Status Codes):
状态码:
1XX 表示服务器信息
2XX 表示请求成功信息
3XX 一般是服务器变化
4XX 客户端请求错误
5XX 服务端请求错误Connection: keep alive /tunnel
Figure 4-13. Four transactions (serial versus persistent)
4. 网络主要结构:
主要结构通常包括 Caches(),Gateways,Tunnels,Proxy,Agents.浏览器发送一个发送 http 请求到服务器服务器过程: 浏览器发送请求 =>通过 DNS 服务器->中间的交换机->防火墙(Gateways)和代理(Proxy)->服务器获取信息(不如读取 Agents)->返回信息.
缓存
是把不必要更新的信息或者不常更改的信息放在离客户端比较近的位置,来提升用户体验和减轻服务器压力的行为. 网络服务中的缓存包括 客户端缓存,CDN 缓存,代理缓存,服务器缓存.
客户端缓存
就是我们通常说的浏览器缓存.一般包括强缓存 和 协商缓存, 当下流行的储存方式有 cookie/localStorage/SessionStorage/ sqlite/ 等等。
强缓存:
服务器可以通过修改返回信息的信息头,在 header 中 加入 Expires (格式为:Expires:Mon,18 Oct 2066 23:59:59 GMT) 或者 cahe-control (Cache-Control:max-age=[time] no-cache/no-store/public/private )来告知浏览器需要缓存的信息
协商缓存
客户端获取资源时 在头文件中增加 Last-Modify/If-Modify-Since 和 ETag/If-None-Match 字段. 服务器通过这些字段判定资源是否更新。 若不更新则启用缓存 返回错误码(304), 否则更新字段 和信息 ,
Cookie/localStorage/SessionStorage/ sqlite 区别
这几个都是储存缓存的方式 Cookie: 不做特殊设置的话会在关闭浏览器时删除,大小限制 4kb,每次向服务器请求会携带 cookie 以验证身份 localStorage:站点永久储存 SessionStorage:用户对页面强制刷新 或者 打开新页面 时更新/被删除 sqlite: HTML5 新增的小型前端数据库
Cookie
Cookie 是一种服务器缓存机制,主要为了解决 HTTP 无状态,对客户信息的记录.
完整流程
客户端请求=》 服务端通过客户端信息生成 cookie 并保存=》客户端请求带上 cookie=》服务端通过验证 cookie 实现状态查询
完整的 cookie 例子
跨域
(CORS) 全称为 Cross-Origin Resource Sharing. 是一种浏览器的安全策略. 当用户访问资源时浏览器会根据返回头判断这些资源是否要展示给用户
跨域发生位置:
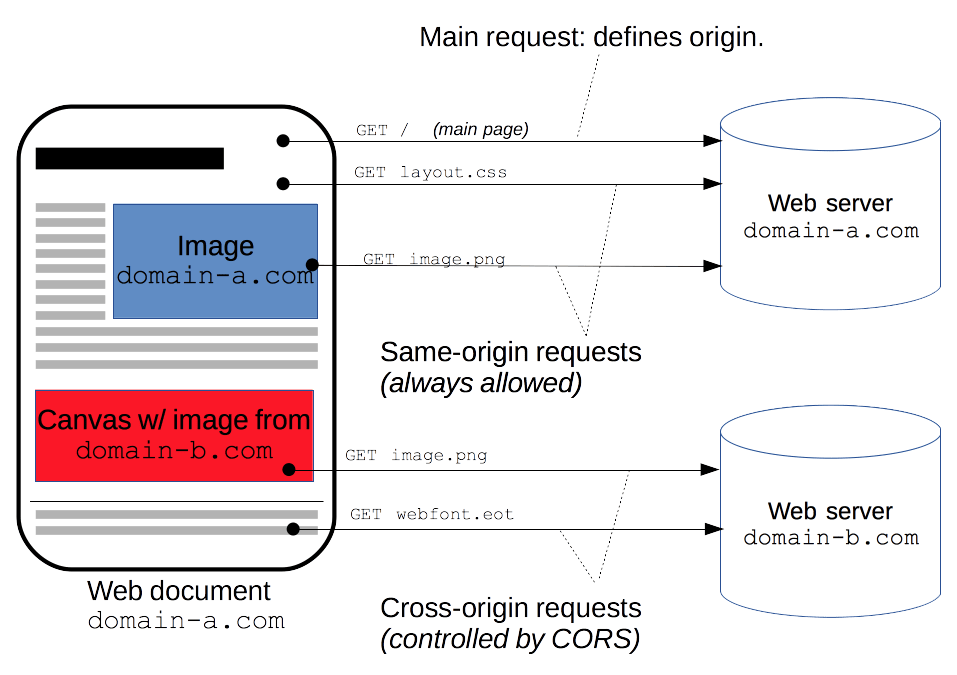 ref:Link
ref:Link
同源策略:浏览器规定 域名/协议/端口均需要相同
例子: 对于 Link | URL | 是否同源 | | ----------- | ----------- | | Link | yes | | Link | No | | Link | No | | Link | No | | Link | No |
为什么要使用同源策略
举个例子:某人做了个假网站 把银行登录界面 嵌套近自己的网页中,除了域名没有任何差别。 用户需要登录银行,打开网站 a, 若没有同源策略,网站 a 外部嵌套可以通过获取用户凭证,并修改或者记录 之后转发给银行来执行其他目的。
Note: 当用户发出请求时 浏览器判断请求是否时简单请求(get/post) a若不为简单请求 浏览器会先通过options 发送预请求,通过之后再发送数据 以防止直接发送请求对服务器端造成不必要的修改.
options 请求不会发送cookie这些用户数据,但可以通过加入头部字串解决造成问题
当下的互联网应用程序采取先后端分离的设计方式,那很可能前后端分布在不同服务器上.造成前后端不同源,调用后端 api 时违反同源策略
解决方法
后端解决:
- 通过设置 Access-Control-Allow-Origin [网页地址/*] 后端可以通过需改返回头, 允许某些网站跨域
- 通过代理服务器 Nginx 做反向代理 使 api 服务器和前端服务器同源
前端解决: 都相对麻烦
- jsonp, 浏览器允许从不同网站加载资源. 比如从 CND 服务器获取图片, 从原服务器获取文字。缺点时只能发 2 送 get 请求.
- 利用中间页传值 比如都写到文件中
- location.hash + iframe 跨域, 浏览器允许 iframe 间 通过 location.hash 传值 但这种只允许子域名传值比如 api.exmaple.com 和 example.com
(ref:Link)
HTTP vs HTTPS
为什么要用 HTTPS?:
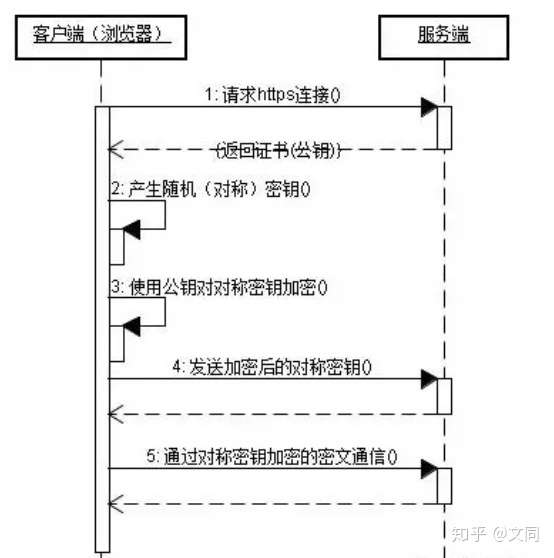
前文提到 HTTP 以明文形式传输,HTTP 协议本身不对信息进行加密,那信息再传输过程中就及其容易泄露,那么就需要用到(SSL(TSL)) 对信息加密.
什么是(SSL(TSL))
SSl:
SSL(TSL)是现代版本用于数据身份验证和加密的一种协议, 技术不仅仅用在 HTTPS 中。 简单来说他由一个 大家都信任的机构发放密钥对(key pair).密钥对里面包括 一个 public key 和一个 private key. public key 用来给数据加密,private key 用来给数据解密并只能解开由 public key 加密的数据. 当用户访问使用 HTTPS 协议网站时候,浏览器会对目标网站请求 public key. 浏览器通过 public key 判断网站是否为安全网站。不合法会对用户提示。
TSL:
TSL 是一种采取 非对称+对称的混合加密手段 这里涉及到很多计算机密码学的知识
RESTFul API design
在现在 web 应用中对程序进行解耦, 即前后端分离,前端程序通过 api 获取后端资源,Restful 是对于后端资源的 api 设计规范
1. 域名规则:
尽量使用私有域名 例如
https://api.example.org/ 或者 资源不多时候使用 https://example.org/api/
2. request 版本号:
在每个 request 中添加版本号,通常把版本号放在 url 中 例如
https://api/example.org/v1
3.资源:
每个 URL 代表一种资源,并且在 url 中 应该不含有任何动词, 一切动作由 method 决定,对于不符合 CRUD 的动作,使用 post 代替. 在 response 中提供资源的信息,如果出现错误,应该返回详细错误,以便排查修改.对于资源集合,可以通过 url 参数对资源进行过滤
/api/articles?author=erickle
返回资源
{
code: 200,
message:'',
data:[..data]
}4.不遵循 restful 接口 的例子:
所有都用资源都用 post
在接口添加 get/Update 的动词
比如:
POST /getBLog POST /postBLog POST /deleteBlog POST /updateBlog
正确做法:
Get /blog POST /bLog DELETE /blog UPDATE /blog
4.pagenation 分页返回数据
通常设计成 offset + limit 设计
GET /blogs?offset=100 & limit=20
返回数据
{
“page”: 1, # 当前是第几页
“pages”: 3, # 总共多少页
“per_page”: 10, # 每页多少数据
“has_next”: true, # 是否有下一页数据
“has_prev”: false, # 是否有前一页数据
“total”: 27 # 总共多少数据
}ref :Link